ShinyApp域名、端口、安全设置及代理

简介
前面我将 ShinyApp部署在阿里云上,阿里云只提供ip,不方便记忆,需要我们自己购买域名,为了方便后续域名解析绑定,所以我在阿里云又购买了域名bnapus-zju.com。域名的解析以及绑定在阿里云上十分简单,这里就不细讲了。下面就是讲一下如何使用Nginx反向代理以及使用HTTPS来保护ShinyApp。
基于SNP进行主成分分析PCA
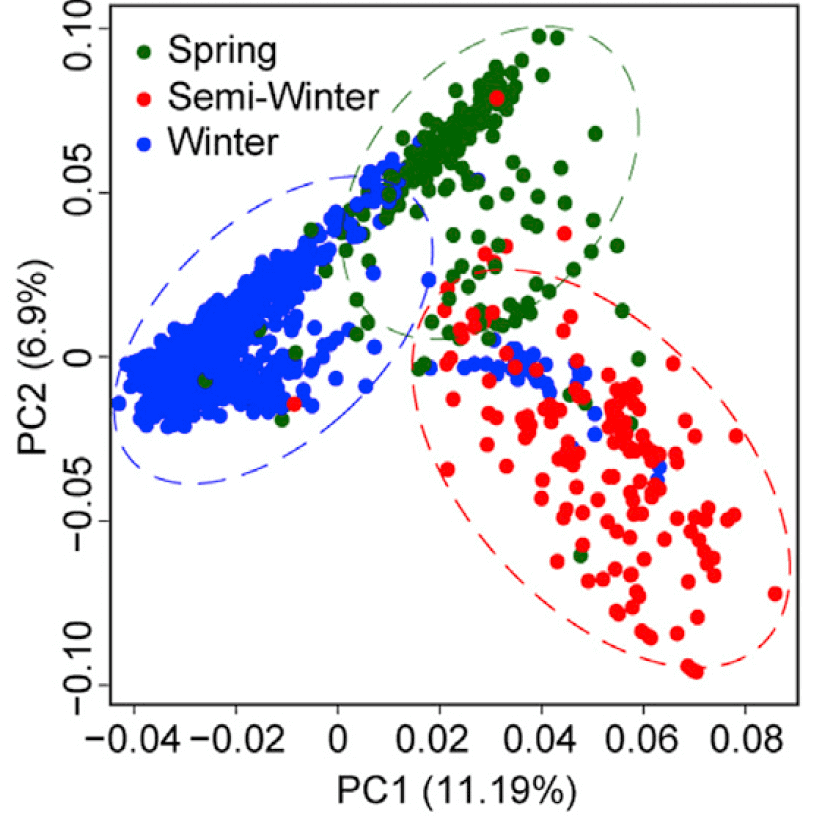
简介
主成分分析(PCA)是一种线性降维方法,通过线性变换简化数据集,提取关键信息对数据进行区分。群体重测序项目往往能得到百万乃至千万级别的SNP,基于SNP进行PCA的软件有很多,主流是下面三种:
使用SNPhylo基于SNP构建群体系统发育树
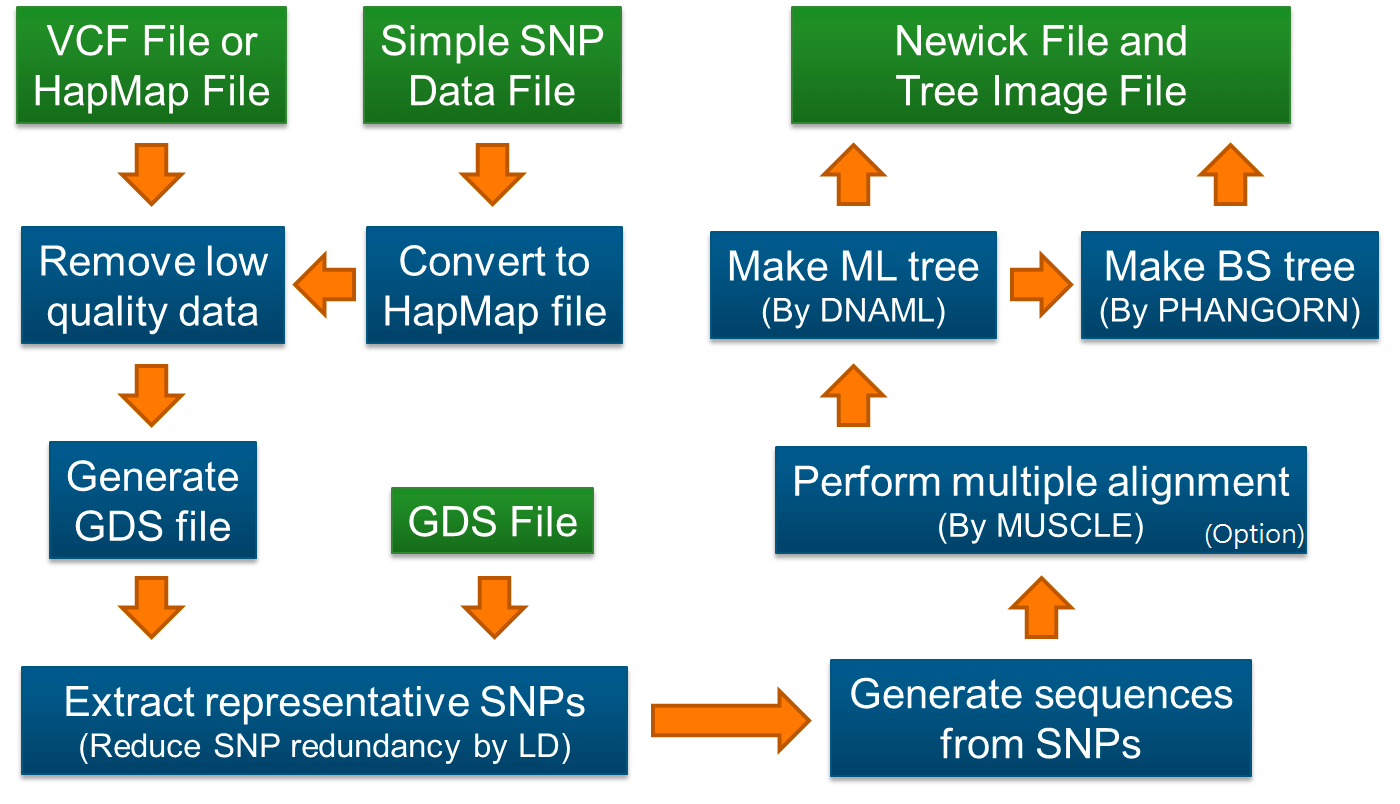
简介
系统发育树是一种推断各种生物之间进化关系的好方法,在进化研究中得到了广泛的应用,得益于测序技术的发展以及成本的不断下降,大量的物种以及群体被测序,产生了海量的基因型数据,在重测序项目中,基于SNP数据进行系统发育树的构建有利于更全面地囊括整个基因组层面的变异进行分析。 SNPhylo是基于SNP数据构建群体系统发育树的一个pipeline,可以接受主流的VCF文件以及HapMap文件,同时其内置了过滤功能,通过对低质量的SNP,连锁不平衡进行过滤,生成用于构建群体系统发育树的输入数据,SNPhylo会调用muscle进行对序列比对,DNAML构树,具体流程如下:
在Ubuntu 20.04/18.04/16.04以及Debian 9/8上安装Java11
Java 11是2018年发布的一个长期支持的版本,不同于Java 8,在Linux上安装Java 11显得更为复杂点,我这里简单记录下,本文主要来源于这篇 博文。

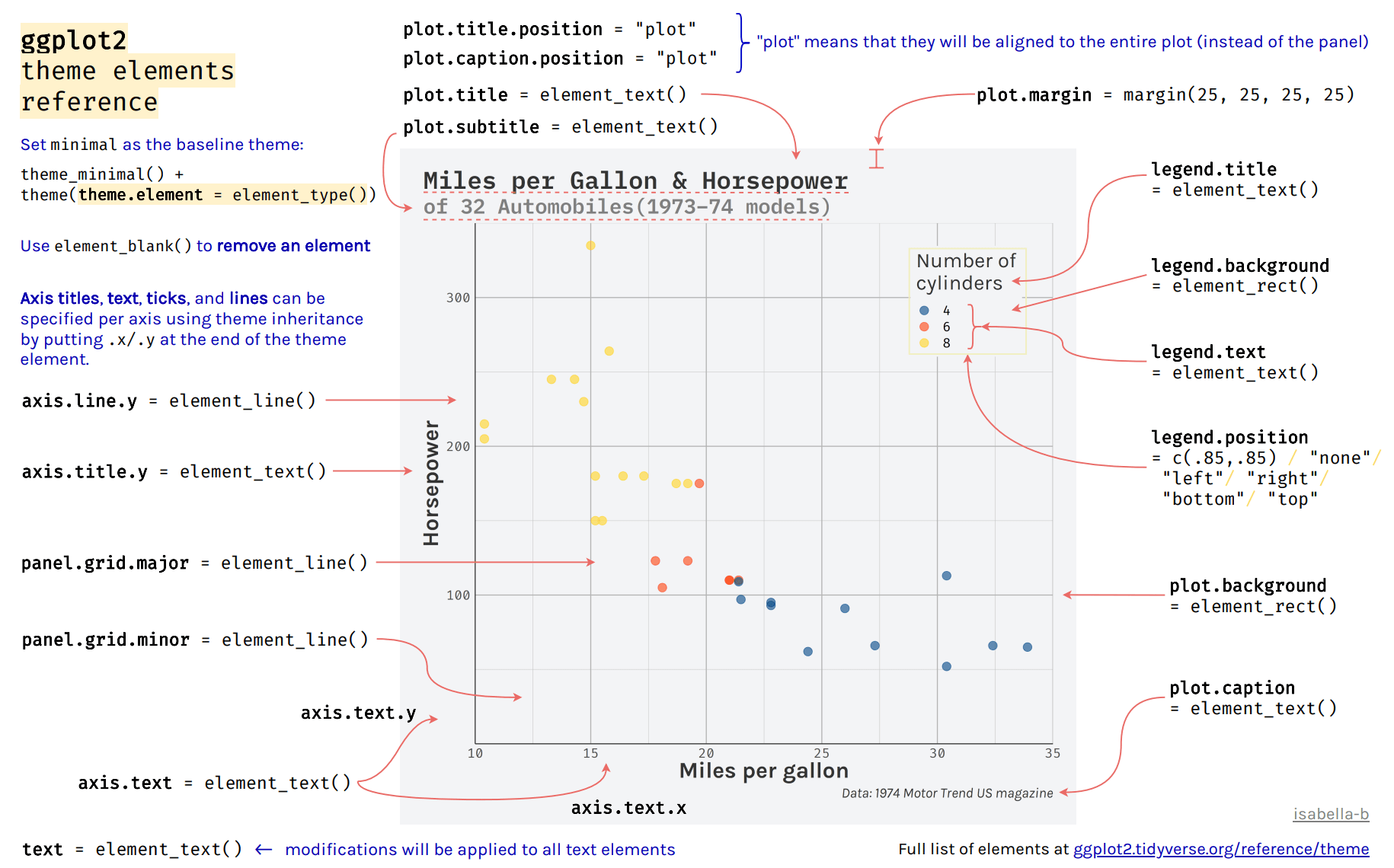
使用override.aes控制ggplot2中的图例外观
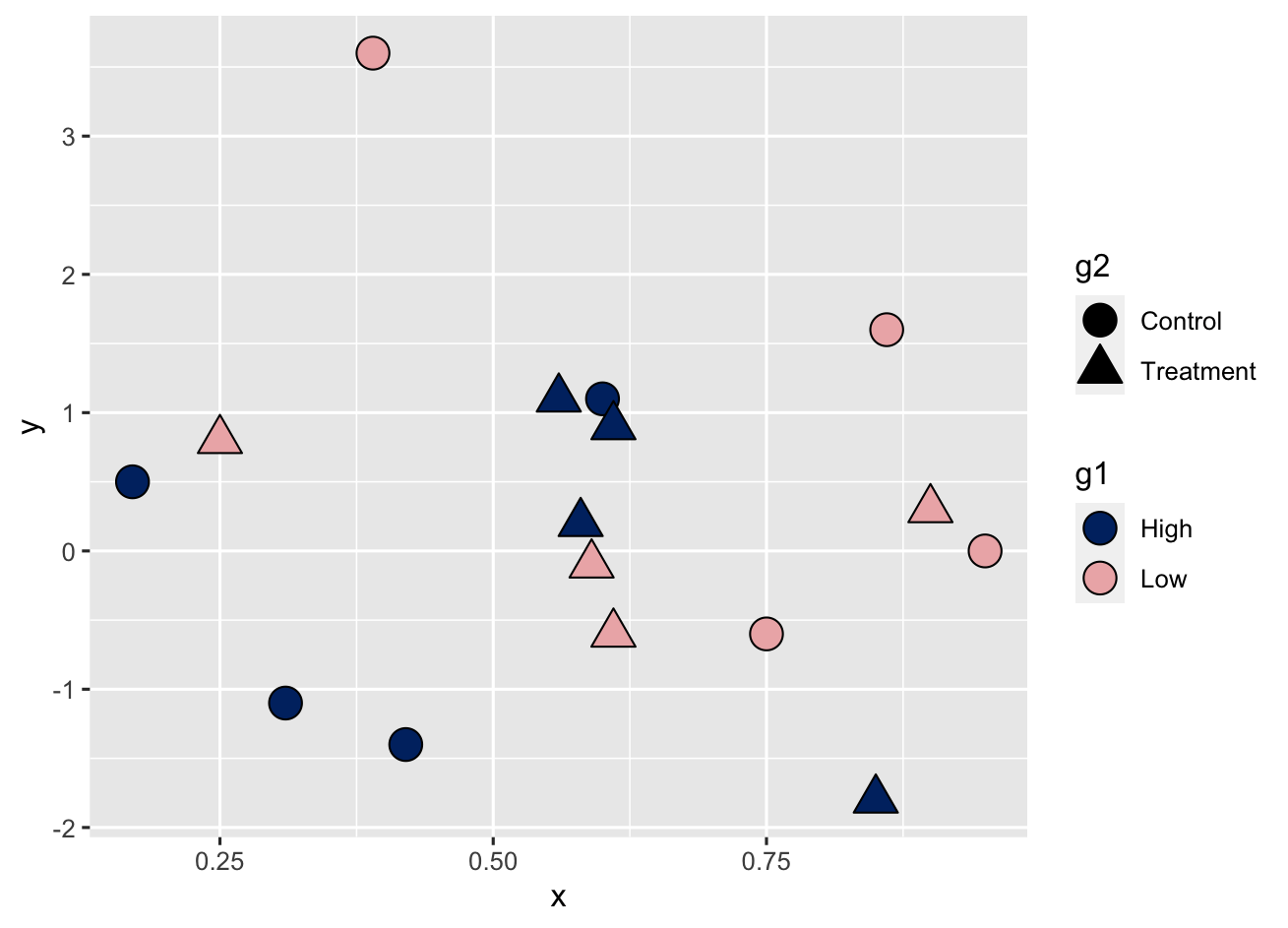
本文来自于https://aosmith.rbind.io/2020/07/09/ggplot2-override-aes/,记录翻译学习
Shiny学习笔记:用户反馈2
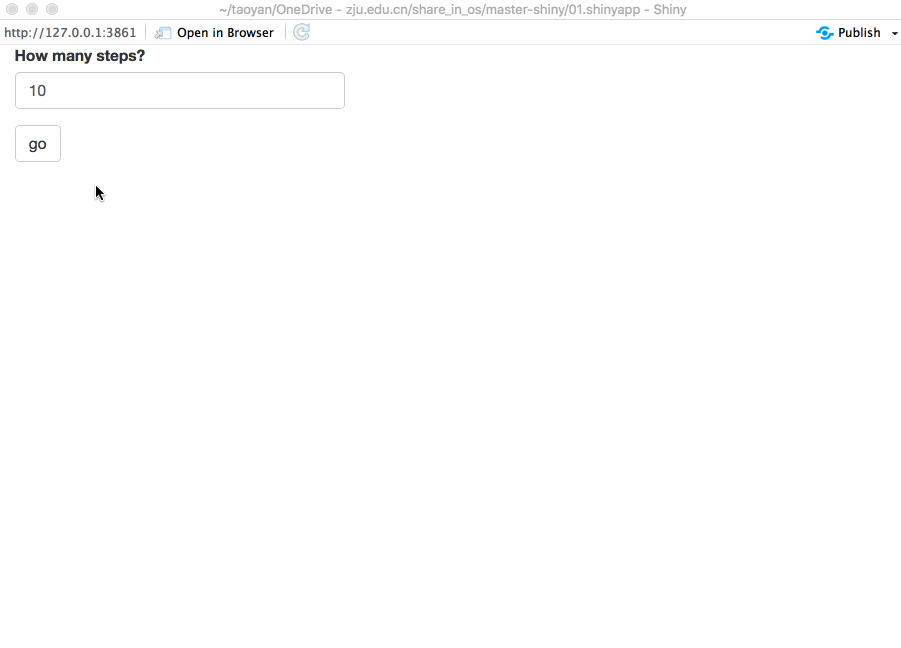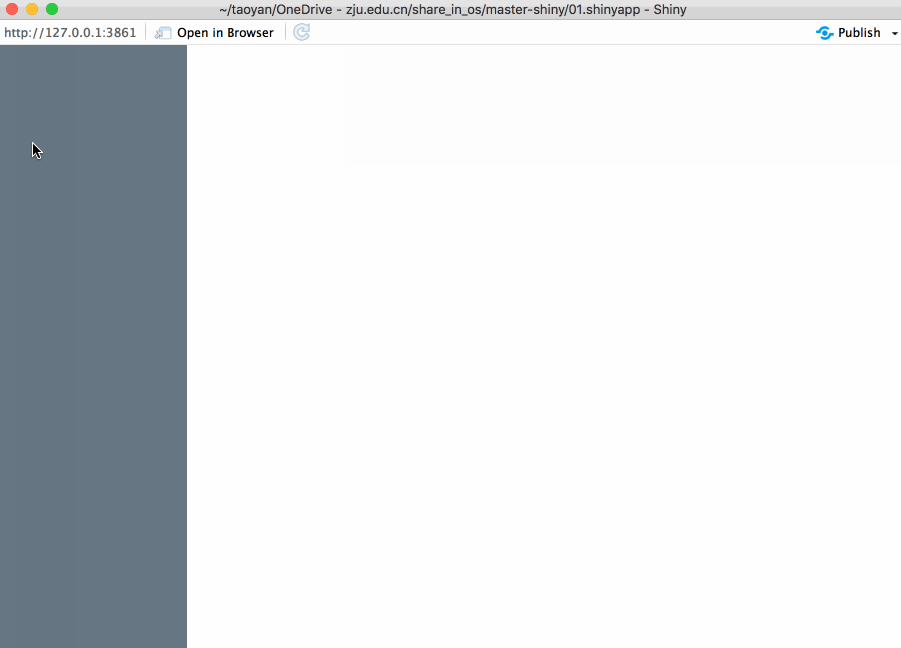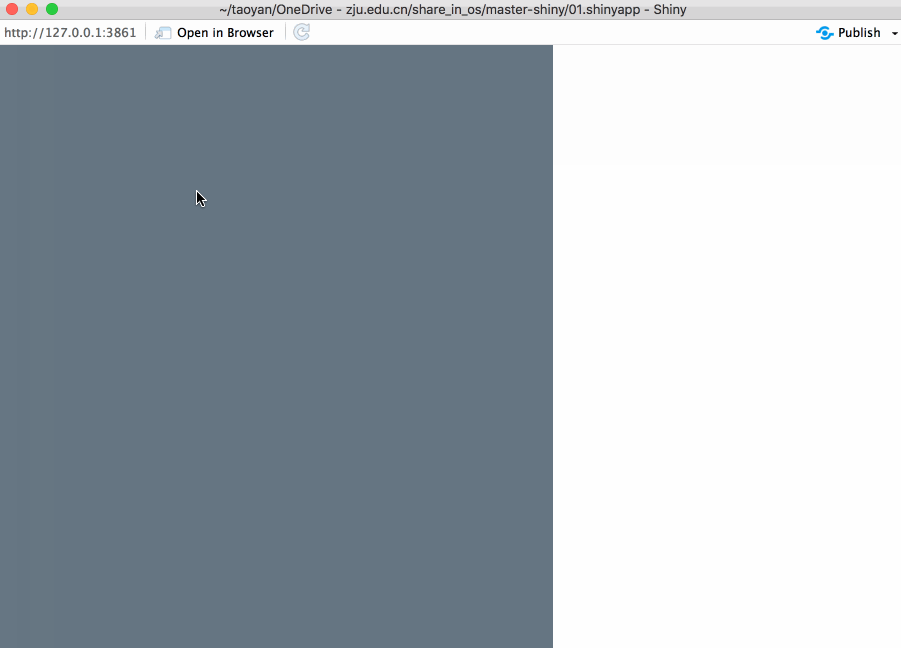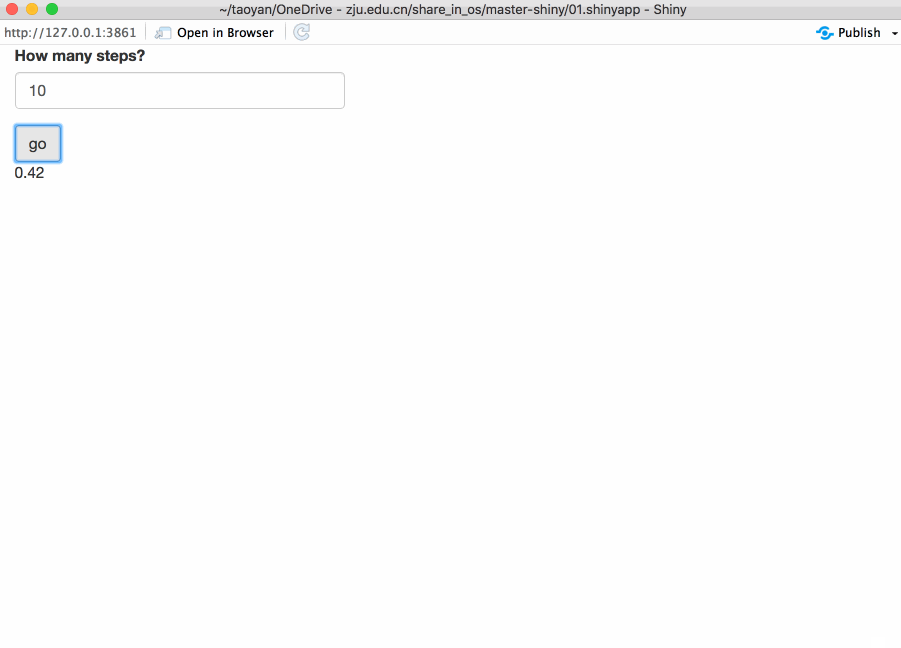
对于运行时间比较长的任务,最佳的反馈形式是进度条(progress bar)。不仅提示你运行到哪一步,还帮助你估算需要运行多长时间。本文主要介绍两种方法:Shiny内置的以及包 waiter。不幸的是这些方法都有一个致命的缺点:如果你想使用progress bar,你需要将一个大任务分解成多个小任务,而且每个小任务的运行时间的大致相同,这就很困难了。
Shiny学习笔记:用户反馈
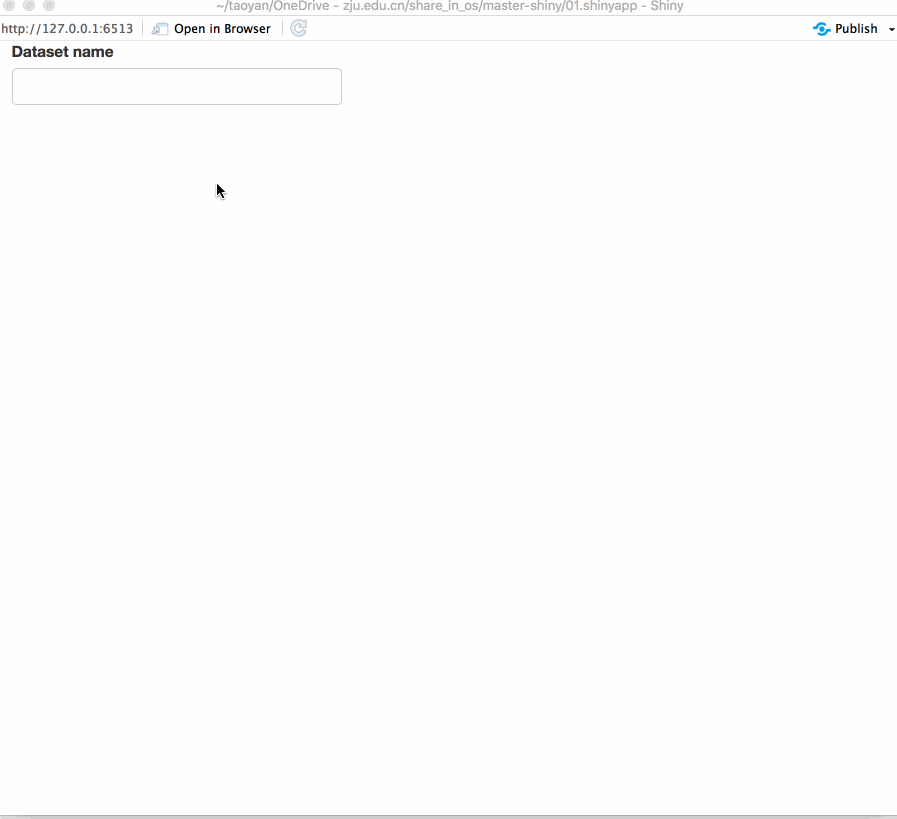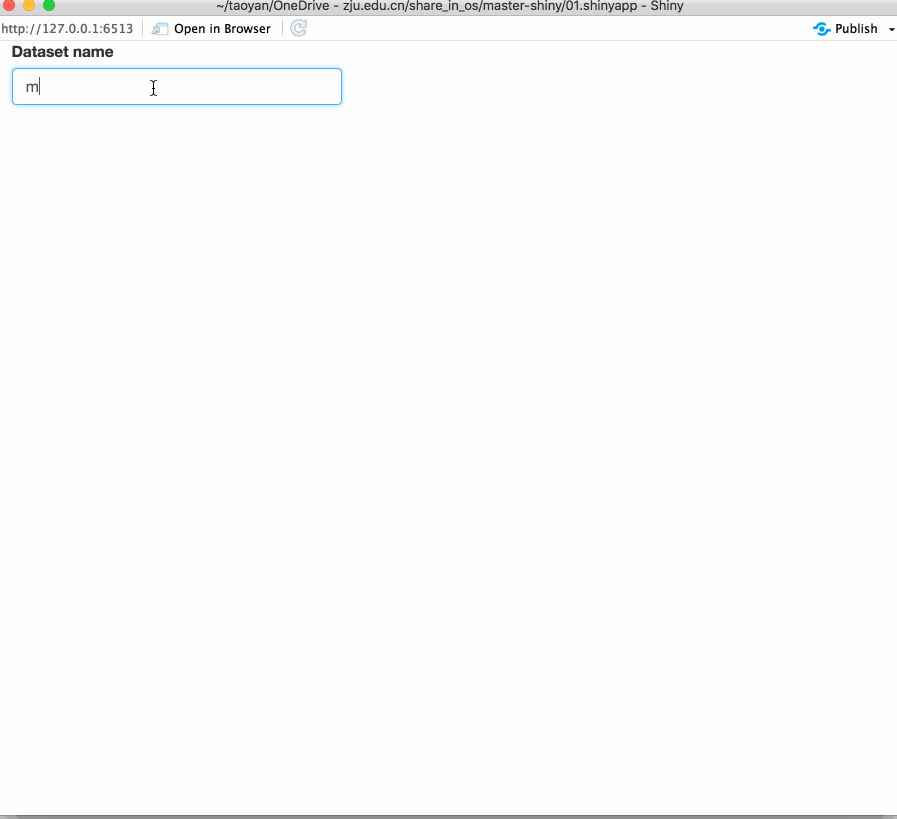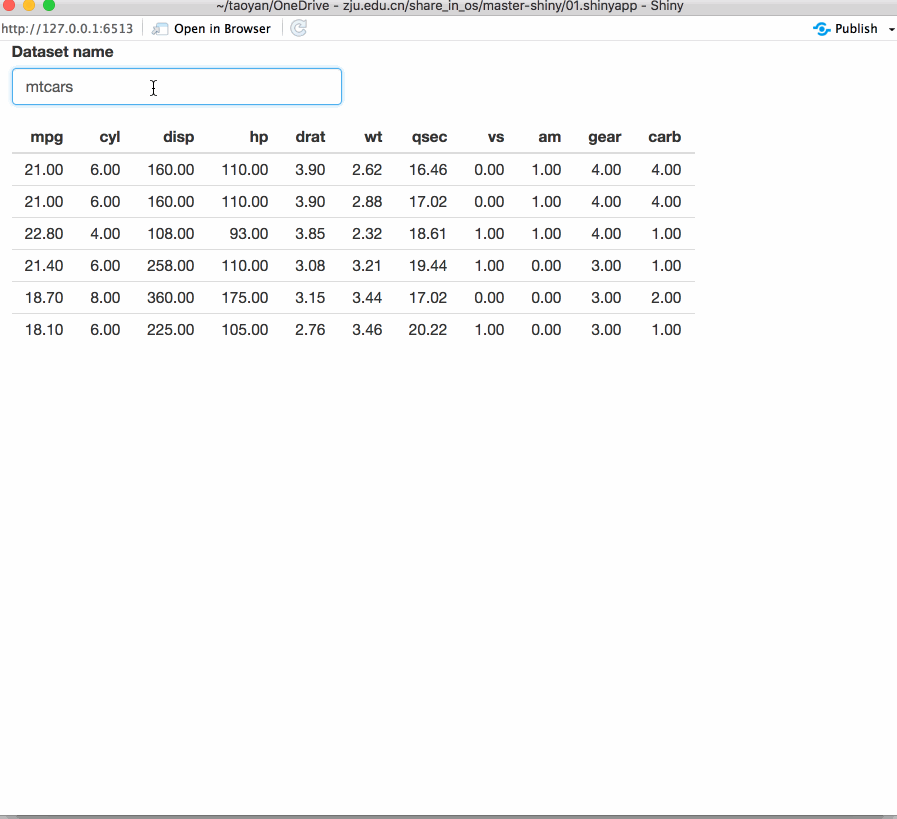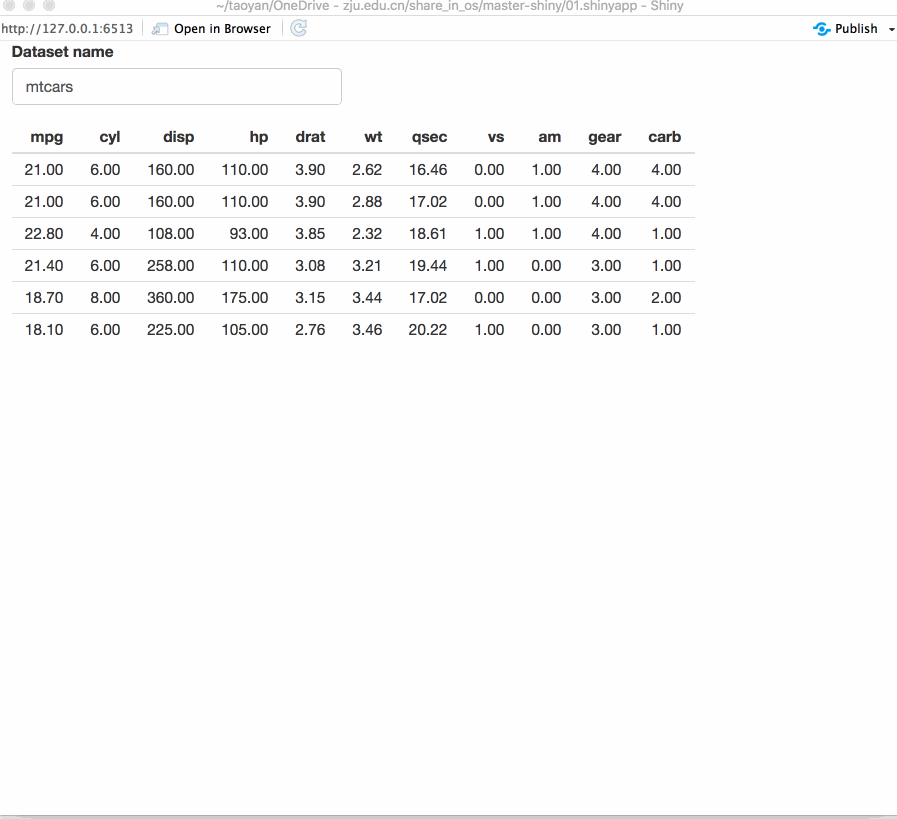
为了使Shinyapp的可用性得到提高,我们需要给用户提供反馈,比如用户输入时消息提醒,运行操作时间过长时提供进度显示等。Shiny自身就提供了多种用户反馈机制,还有一些十分优秀的扩展包也提供了一些方法。
将数据保存为R的数据格式:RDS,RDATA
在R里面我们一般将数据保存为txt,cvs或者Excel格式,这有利于我们在电脑中打开浏览这些文件,但是这些保存格式无法将数据结构嵌入进去,比如数据列类型(数值型,字符型或者因子型),为了解决这些问题,我们可以将数据保存为R数据格式