Researcher
Hunan Agricultural University
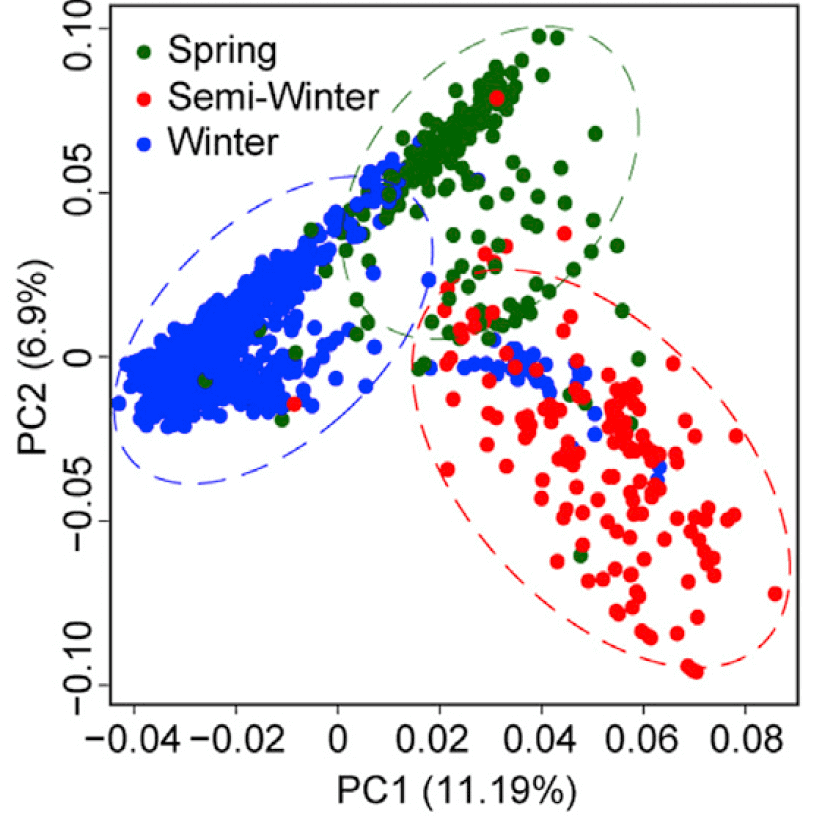
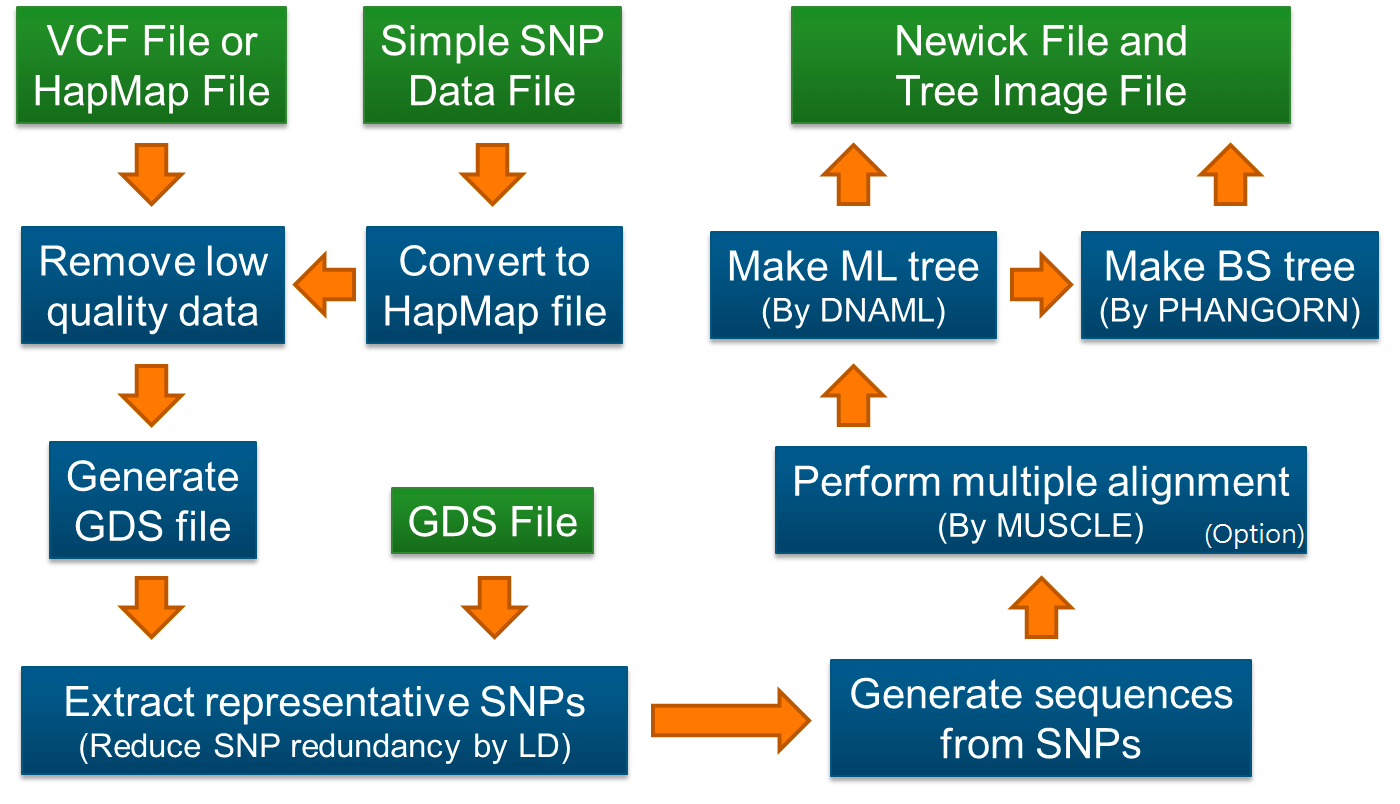
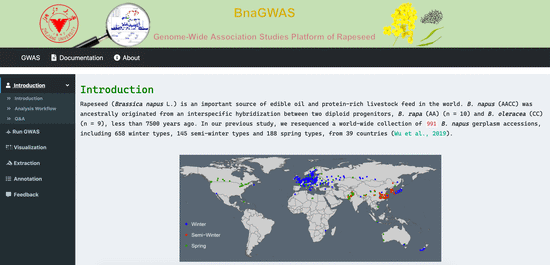
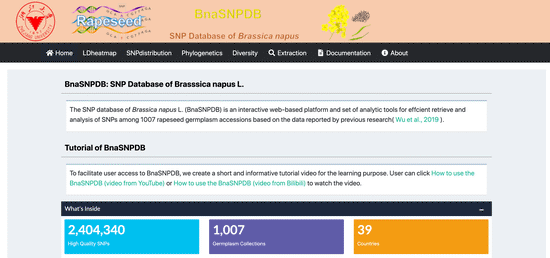
I am a lecturer at College of Agronomy, Hunan Agricultural University (HUNAU), Changsha, China. My Ph.D research work covers a range of issues: Population Genetics Evolution and Ecotype Divergence Analysis of Brassica napus, Genome-wide Association Study (GWAS) of Agronomic Traits. Currently, I am interested in Transposable Elements Insertion Polymorphisms (TIPs) in Crop Population and genetic basis such as SV, CNV and TIPs etc. Now my research focus on Crop Stress and Improvement.
I am broadly interested in bioinformatics, data integration and visualization.
Interests
- Python & R Program
- Bioinformatics
- Machine Learning
- Data Science
- Data Visualization
- Open Source
Education
-
PhD Candidate in Crop Genetics and Breeding, 2016
Zhejiang University (ZJU)
-
BSc in Crop Science, 2012
The College of Agriculture and Biotechnology, Zhejiang University (ZJU)