如何选择使用哪个*apply函数
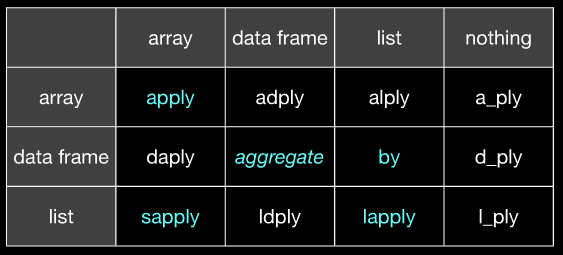
简介
R有很多的*apply函数,然后plyr包提供了很多函数来替换*apply函数,但是我们还是经常用到*apply函数,很多时候不知道选择使用哪个*apply函数。
apply函数
当需要对矩阵(或更高维的矩阵数据)的行或列进行函数操作的时候,用apply函数,不建议对dataframe使用,因为apply会第一时间将之转换为矩阵。
# Two dimensional matrix
M <- matrix(seq(1,16), 4, 4)
# apply min to rows
apply(M, 1, min)
[1] 1 2 3 4
# apply max to columns
apply(M, 2, max)
[1] 4 8 12 16
# 3 dimensional array
M <- array( seq(32), dim = c(4,4,2))
# Apply sum across each M[*, , ] - i.e Sum across 2nd and 3rd dimension
apply(M, 1, sum)
# Result is one-dimensional
[1] 120 128 136 144
# Apply sum across each M[*, *, ] - i.e Sum across 3rd dimension
apply(M, c(1,2), sum)
# Result is two-dimensional
[,1] [,2] [,3] [,4]
[1,] 18 26 34 42
[2,] 20 28 36 44
[3,] 22 30 38 46
[4,] 24 32 40 48
lapply函数
当需要对list的每一个元素进行函数操作的时候,用lapply函数,返回的也是一个list
x <- list(a = 1, b = 1:3, c = 10:100)
lapply(x, FUN = length)
$a
[1] 1
$b
[1] 3
$c
[1] 91
lapply(x, FUN = sum)
$a
[1] 1
$b
[1] 6
$c
[1] 5005
sapply函数
当需要对list的每一个元素进行函数操作,但是希望返回的是向量而不是list,用sapply函数,因此如果当你发现正在用unlist(lappply(...))的时候,直接用sapply吧
x <- list(a = 1, b = 1:3, c = 10:100)
# Compare with above; a named vector, not a list
sapply(x, FUN = length)
a b c
1 3 91
sapply(x, FUN = sum)
a b c
1 6 5005
sapply高级用法:sapply会强制性的将结果生成为数组
比如如果我们的函数返回的向量具有相同的长度,sapply会将返回的每一个向量作为列组成矩阵
sapply(1:5,function(x) rnorm(3,x))
[,1] [,2] [,3] [,4] [,5]
[1,] 3.5989315 2.073428 2.011637 3.679340 6.354837
[2,] -0.2045726 1.848288 3.453982 2.810947 5.231291
[3,] -0.4243982 1.141556 2.675633 3.268007 3.128108
如果函数返回的是二维矩阵,那么sapply会将每一个返回的矩阵当做一个长向量处理
sapply(1:5,function(x) matrix(x,2,2))
[,1] [,2] [,3] [,4] [,5]
[1,] 1 2 3 4 5
[2,] 1 2 3 4 5
[3,] 1 2 3 4 5
[4,] 1 2 3 4 5
除非指定参数simplify="array",此时sapply会返回一个数组
sapply(1:5,function(x) matrix(x,2,2), simplify = "array")
, , 1
[,1] [,2]
[1,] 1 1
[2,] 1 1
, , 2
[,1] [,2]
[1,] 2 2
[2,] 2 2
, , 3
[,1] [,2]
[1,] 3 3
[2,] 3 3
, , 4
[,1] [,2]
[1,] 4 4
[2,] 4 4
, , 5
[,1] [,2]
[1,] 5 5
[2,] 5 5
vapply函数
vapply函数其实跟sapply函数一样,就是提供了FUN.VALUE参数来设置返回值的行名,相对于sapply节省了一行代码,使代码更流程健壮,一般不用,直接用sapply就好了
vapply(1:5,function(x) matrix(x,2,2), FUN.VALUE = c("a"=0,"b"=0,"c"=0,"d"=0))
[,1] [,2] [,3] [,4] [,5]
a 1 2 3 4 5
b 1 2 3 4 5
c 1 2 3 4 5
d 1 2 3 4 5
mapply函数
当输入数据含有多类(等长度的)数据结构(向量,数据框,矩阵,列表等),想依次对每所有数据结构的第1个元素进行函数操作,第2个元素进行函数操作…,此时就用mapply,返回的是类似于sapply的向量或数组
#Sums the 1st elements, the 2nd elements, etc.
mapply(sum, 1:5, 1:5, 1:5)
[1] 3 6 9 12 15
#To do rep(1,4), rep(2,3), etc.
mapply(rep, 1:4, 4:1)
[[1]]
[1] 1 1 1 1
[[2]]
[1] 2 2 2
[[3]]
[1] 3 3
[[4]]
[1] 4
还有一个Map函数,是mapply的简单版,返回列表
Map(sum, 1:5, 1:5, 1:5)
[[1]]
[1] 3
[[2]]
[1] 6
[[3]]
[1] 9
[[4]]
[1] 12
[[5]]
[1] 15
tapply函数
当需要对向量的子集进行函数操作,用tapply,该子集一般是由其它向量决定,一般是因子(factor),tapply理解起来有点难度,实际上它的帮助文档都很难看明白:
apply a Function Over a "Ragged" Array
Description:
Apply a function to each cell of a ragged array, that is to each
(non-empty) group of values given by a unique combination of the
levels of certain factors.
Usage:
tapply(X, INDEX, FUN = NULL, ..., simplify = TRUE)
大家看懂了吗?咋一看是很难理解的,举个例子理解一下
#A vector:
x <- 1:20
#A factor (of the same length!) defining groups:
y <- factor(c(rep("a",1),rep("b",9),rep("c",10)))
#Add up the values in x within each subgroup defined by y:
tapply(x,y,sum)
a b c
1 54 155
可以看出,很简单就是个group by操作,上面理解起来就是分成三组,分组个数为1,9,10,sum函数将第一个数加起来为1,将2-10个数加起来是54, …